車両検知アルゴリズムの謎を解き明かす

(写真:Zapp2Photo/Shutterstock.com)
車両検知は謎が多いように見えますが、この技術は結局のところ、指定エリアの画像の画素特徴量を計算し、その特徴に基づいて対象オブジェクトがどのカテゴリに分類されるかを判断する数式です。オブジェクトの検知方法は、一般的には特徴量抽出とカテゴリ分類という2段階に分けられ、サポートベクターマシン(SVM)と輝度勾配方向ヒストグラム(HOG)を併用するのが一般的です。
今回は、広く利用されている車両検知アルゴリズムをご紹介しますが、特に下記の項目に焦点を当て、アルゴリズムに隠れる謎を解明するとともに、読者の皆さんに機械学習プロセスについて理解していただこうと思います。
- 適用シナリオの概要
- HOG特徴量の算出に関する詳しい解説
- SVMワークフローの概要
- 比較とまとめ
適用シナリオの概要
車両検知技術は、こちらの例に示す通り広い範囲ですでに実際に利用されています。私たちが普段運転する個人の乗用車でも、複数の車載用バックカメラを搭載しているものがあります。このシステムは、車両後方の一定距離以内に別の車両が入り、追い越そうとしてきたときに起動します。車両後方に別の車両が検知されると、アラートが発生し、速度を落とすよう促されます(図1)。また、自動運転の分野でも応用されており、周辺の車の位置から各車の速度、距離、及びその他の要素を分析し、それに応じて車の進路を自動調整します。

図1:バックカメラは画像に映る車両を検知し、四角で囲うことで車両の位置を示すことができます。(写真:Just Super/Shutterstock.com)
車両検知システムは、交通規制や道路状況の監視に広く利用されています(図2)。例えば以下の写真のシステムはトンネルの入り口に設置されており、毎日一定の時間枠で交通量を計測し、その状況に応じた交通規制を実施することで交通事故の低減を図り、またドライバーに渋滞に関する情報を提供します。これによってドライバーは渋滞を避けるルートを選ぶことができます。さらに交通量の統計データを空港または鉄道駅の駐車場にも利用することができます。ビッグデータを分析することで需要の高い駐車場を見つけ、それに応じてスタッフが対応したり、人材を多く配置したりすることができます。
車両検知システムを使った信号は、他の技術を組み入れることで指定した信号機周辺の交通量を検知することができ、ビッグデータとAIを利用してその信号機に適切で合理的な時間間隔を計算・決定することができます。

図2:車両検知システムを道路状況の監視に適用(写真:PaO_STUDIO/Shutterstock.com)
HOGとSVM併用アルゴリズム
(40 − 16) / 8 + 1 = 4
HOGとSVMを組み合わせて歩行者を検出する方法は、元々フランスの研究者Dalal氏が2005年にカリフォルニア州サンディエゴで行われた「コンピュータビジョンとパターン認識会議」において提案したものです。現在のHOG+SVM手法は進化を遂げ、車両や車線の位置を含むあらゆるオブジェクトを検知することができます。
HOG特徴量の算出
1. HOGは局所特徴量の抽出アルゴリズムであるため、多くの特徴量が抽出されたとしても、複雑な背景を含む大きい画像の中の1つのオブジェクトを検出する目的には適していません。対象オブジェクトを検出できるように画像を小さくカットする必要があります。対象物が車両である場合、きちんとした結果を得るには、その車両が画像の80%を占めなければならないということが実験的に証明されています。カットされた局所画像は、ブロックに分割され、各ブロックは個々のセルからなる特徴量として抽出されます。
(1つの画像の中のセルは複数のピクセルで構成され、ブロックは複数のセルで構成されます。)
HOG特徴量の算出プロセスについては、以下の図3を使って解説します。
まずは全体の画像をカットして、40ピクセル×40ピクセルの画像にします。次に、以下の変数を定義しなければなりません。
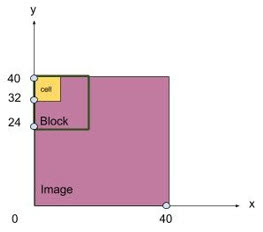
図3:カットされた画像内のブロックの動作を説明するために、この図では、1ブロック内に4つのセルがあり、それぞれの1辺が16ピクセルであることを示しています。次に、この画像はカットされ、長さ40ピクセル×幅40ピクセルの画像になります。対応する刻み幅は1であり、これは一度に1ピクセル分動作するという意味です。(図:Mouser提供)
A. 移動工程(s)を定義します。例:s=1
B. ピクセル単位でセルのサイズを定義します。例:8×8
C. ブロックサイズを定義します。例:1ブロックあたり2×2=4セル
D. 最後にビン数を定め、必要に応じてその値を設定します。例:ビン数=9
各ビンは、算出された勾配方向ヒストグラムの累積値を保存するために使用されます。これについては後ほどさらに詳しく説明します。
2. インプットされる画像と色は標準化することで光や影による影響を抑え、画像内のオブジェクトの検出精度に影響がでないようにします。この作業には、ガンマ補正やグレースケールへの変更などが適用されます(ガンマ補正の原理についてはここでは省略します)。
3. 勾配のサイズを計算します。
計算方法は、1つのセルに属する部分ブロックの例を使って説明します(図4)。使用する計算式は、以下に示す通り、ピクセル値25の中点を算出するためのものです。
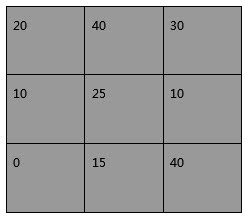
図4:1つのセルに対する部分ブロックサイズとピクセル値(図:Mouser提供)
畳み込みカーネル手法に基づいた合理的な定義を使用すると、[-1, 0, 1]が最も効果的であることが分かります。畳み込みカーネルの[-1, 0, 1]とは、各ピクセルの勾配振幅方向を計算するためのマトリクスであると理解することができます。よって横方向(x軸のプラス(右)方向)には[-1, 0, 1]、縦方向(y軸のプラス(上)方向)には[-1, 0, 1]Tを使用することで、画像領域の各ピクセルに関する横方向と縦方向の勾配情報を算出することができます。2つの情報の平方和やルート記号によって、その時点での勾配方向が分かります。使用される計算式は以下の通りです。

したがって、ピクセル値25の中点における横方向は、図5に示すように算出されます。
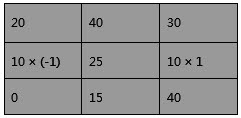
図5:ピクセル値25の中点の横方向に関するピクセル値を算出(図:Mouser提供)
計算式:
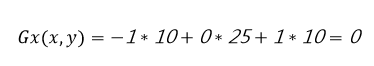
したがって、ピクセル値25の中点における縦方向は、図6に示すように算出されます。

図6:ピクセル値25の中点の横方向に関するピクセル値を算出(図:Mouser提供)
計算式:

4. 対応する勾配方向は、以下の計算式を使用して算出されます。
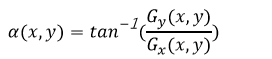
5. 1つのセルの全ピクセルに対して手順3から4までを繰り返し、値をすべて合計すると、各セルの9つの勾配方向における勾配の統合プロットを取得することができます(図7)。
6. 画像ブロックのHOG特徴量について算出します。つまり含まれるセルの特徴を結び付けます。
7. 次に、全体画像のHOG特徴量について算出します。つまり含まれるブロックの特徴を結び付けます。
8. 特徴の数値を算出する方法
上記例のブロックがx軸とy軸の両方向に4ステップずつ動きます。
(40-16)/8+1=4
各ブロックには4セルずつあります。
2*2=4
特徴の数値を計算する数式は以下の通りです。

このように例の画像に対して計算された特徴の数値は、576となります。
9. 次に取得した勾配ベクトルを標準化します。標準化の最大の目標は、過剰適合を防止することです。過剰適合は学習データセットを分類するにはよいかもしれませんが、テストデータの検出率は非常に低くなり、私たちの目的には明らかに適していません。例えば(0, 200)の間に分散された固有値を取得した場合、機械学習の特徴量の標準化に使用するのと同じアプローチで、200未満の数値が特徴量の分散に影響を与えないようにしなければなりません(200に適合する全体の傾向から外れていると、過剰適合が発生します)。そのため、特徴量の分散を一定の間隔に標準化する必要があります。Dalal氏は自身の論文の中で、「L2ノルムを使用した結果は非常に満足度が高かった」と述べています。
(ここでの0, 200は、固有値の範囲を示しています。)
10. 対応するラベルに合った特徴がSVMに送られ、分類子を学習させます。
勾配方向ヒストグラムとビンの数値
Dalal氏は論文の中で「この手順の目的は、画像内で検知されたオブジェクトの外観に対する感度を低く保ちながら、局所画像領域の関数に対する量子化勾配方向を示すことである」と述べています。
勾配のサイズは、勾配方向に基づいてビンの中に挿入され、方向を定める際は2つの方法を使うことができます。
符号なしのアプローチは、車両またはその他のオブジェクトの検出に適していますが、符号付きのアプローチは、車両またはその他のオブジェクトの検出に適していないことが証明されています。しかしこのアプローチは、画像がズームイン、ズームアウト、または回転している場合に役立ち、その後ピクセルを元の位置に戻すことができます。詳細については参考資料の5番目のリンクをクリックしてください。
1. 符号なし:(0, π)
符号なしの補間について詳しく見ていきます。
今回は、補間について解説するにあたり3つの表を使います。それぞれの表の1行目は算出された振幅、2行目は定めたビン数で180度を割ったビンの方向値を示します。3行目は、0から始まるビンのシーケンス番号です。
画像は必要に応じたビン数に分けることができます。例えば、1セルあたり9つの方向を持つ勾配ヒストグラムを使用するため、9つのビンに分ける場合、各ビンは20度のエリアをカバーします。上で計算された振幅が各ビンに挿入され、各ビンの振幅を合計した数はヒストグラムの縦軸に相当し、横軸はビン値の範囲に相当します。この場合は(0, 8)です。
補間方法
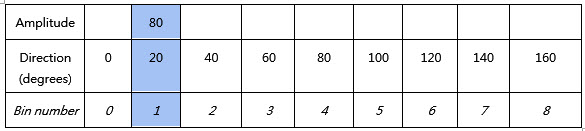
1ピクセルの振幅が80、方向が20度の場合、これらの値はそれぞれ表1の青いエリアに挿入されます。
表1:1ピクセルの振幅が80、方向が20度の場合、以下のようにそれぞれの個所に挿入されます。
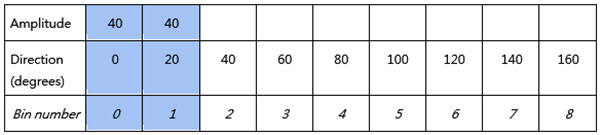
振幅が80、方向が10度の場合、これらの値はそれぞれ表2の青いエリアの2箇所に別々に挿入されます。
表2:1ピクセルの振幅が80、方向が10度の場合、以下のようにそれぞれの個所に挿入されます。
振幅が60、方向が165度の場合、これらの値はそれぞれ表3の青いエリアの2箇所に別々に挿入されます。
(180度と0度は、方向は同じですので、振幅は2つのビンに1:3の比で挿入されます。)
表3:振幅が60、方向が165度の場合、以下のようにそれぞれの個所に挿入されます。

上の表1は、方向の値がビンの対応する値と全く同じときに使用する補間方法、表2は、方向の値が2つのビンの値の間に該当するときに使用する補間方法、また表3は、方向の値がビンの最大値よりも大きいときに使用する補間方法をそれぞれ示しています。これら3つの計算の原理に応じて、単位としてセルを使って計算する場合、計算後に全ピクセルの振幅数を合計します。例えば、上記サンプルのビン番号0について40と15の振幅値を得た場合、ビン0に対するヒストグラムのこれまでの合計値は55以下となります。ビン1から8までの全セルに対する振幅値を同じ方法で算出し、合計します。最終的には以下の図7のようなヒストグラムができます。X座標は勾配方向、Y座標は勾配振幅を示します。

図7:勾配ヒストグラムの例:横軸はビン番号、縦軸は算出された振幅です。図の縦軸の数値は実際の数値ではありません。例えば上の3つの表に示すビン1の振幅値を合計すると、80 + 40 + 0 = 120となり、ヒストグラムのy軸は120になります。ビン1に対する計算を続けると、その数値は累積されていきます。(図:Mouser提供)
実験の結果、対象に9つのビンと単方向の補間を使用した時の結果が最も良いことが分かりました。
2. 符号付き:(0, 2π)
方向の値の前にプラスまたはマイナス符号を付け、9つのビンを定める場合、それぞれのビンに割り当てられる角度範囲は(0, π/9°)となります。例えば、2番目のビンのプラスの値が20–40の範囲(青いセクター)に挿入される場合、マイナスの値は200–220の範囲(青いセクター)に挿入されます(図8)。
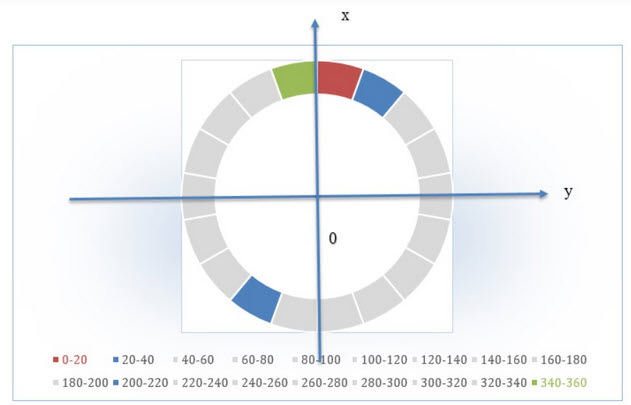
図8:符号付き補間の場合、各セクターは1つのビンがカバーする角度範囲を表します。例えば赤はビン1で0~20度の範囲です。時計回りに進み、最後の緑は340~360度です。青のエリアは両方向におけるビンを示します。(図:Mouser提供)
SVMワークフローの概要
SVM(サポートベクターマシン)は、超平面を使って空間を2つのクラスに分類します。二次元空間は、シンプルにyが存在し、yが成立する空間として理解してください。
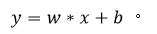
yの値によって、サンプル値がプラスであるか、マイナスであるかが決まります。ただし最適な超平面を決定するために、サポートベクターと最大間隔を導入します。私たちの目標は、超平面を見つけ、その超平面に最も近い点と点の間隔を最大にすることです(図9)。

図9:赤い線は超平面を指し、点線上にある点はサポートベクターで、算出された値は1(プラスのクラス)と-1(マイナスのクラス)です。青い点はプラスのサンプル、緑の点がマイナスのサンプルです。ここでの目標は、点線と点線の間の距離を最大にできる値を見つけることです。理由は、この距離が大きいほど、二値分類モデルの質が高いためです。(図:Wikipedia)
現実のデータは複雑性が高いため、必要に応じてカーネル関数を導入します。これにより、高次元データに低次元データをマッピングし、最適な超平面を見つけることで線形分離不可能データ(図10)を線形分離可能にします。
図10:赤い線で囲まれた点は、二次元空間の青い点から分離できないため、カーネル関数を使用して、これらの点をもっと次元の高い座標系に変える必要があります。(図:Mouser提供)
ただしSVMは、他の全ての点との類似性を計算するため、計算負荷が高く時間もかかります。そのためSVMは、データ量の少ない二値分類モデルの学習に適しています。複数のカテゴリが関与する場合は、複数のモデルを個々に学習します。さらに、国立台湾大学の教授陣が開発したオープンソースの2つのツールが現在広く使われています。LibSVMとLiblinearであり、SVM技術を使って大量データ用に開発されました。
SVMはパラメーターの影響を強く受けます。LibSVMまたはLibLinearの学習期間は、ペナルティ項のCと荷重係数wに注目することが重要です。ペナルティ項のCが大きいほど学習プロセス中の分類効果が高いという意味です。ただしCが大きすぎると、過剰適合が起こる可能性があります。つまり学習サンプルの分類精度は非常に高くても、テスト精度は非常に低くなるということです。中心のデータセットから外れたデータポイントは必ず存在し、Cのサイズは、その外れ値を低減させる私たちの意欲を示します。Cの値が大きすぎるということは、私たちが外れ値を捨てる気がないということになるため、そのモデルは学習セットにはよいですが、テストセットには適しません。荷重のwは、プラス及びマイナスのサンプルを表し、検出対象を増やしたい場合は、プラスのサンプル荷重を増やすことができます。ただし、あまり増やすと誤検出率(FP)が上がります。逆にマイナスのサンプルを減らすと、誤検出率(FP)は下がりますが、目標物検出率(TP)も必然的に下がります。
筆者によるシンプルな実験では、100万のデータポイントと1152次元の特徴量を使用して、Windows 10を動作させながら2つのCPUと60GのRAMを使い、学習用のスレッドを18個開くのに20分かかりました。そのため、Liblinearライブラリを利用して大規模コーパスで学習をするか、または利用可能なコンピューターメモリを増やすことをお勧めします。
比較とまとめ
今回は、車両検知という観点から特徴量の算出に焦点を当て、さらにSVMの分類方法についても簡単に紹介しました。車両検知にHOG特徴量を使用する場合は、9つのビンに1,000以上の次元数を持たせ、特徴量に対して符号なしの補間をすること、また特徴量の分散が偏っている場合は標準化することを推奨します。SVMについては、必要に応じてカーネル関数を選択することができます。またLibSVMライブラリを利用すれば、大規模データに基づいたモデルを学習させることができます。低次元空間を効果的に高次元空間にマッピングするSVMのカーネル関数メカニズムは、線形分離不可能の問題を解決してくれます。SVMの計算負荷は、サポートベクターの数によって決まり、最終的な決定関数は、少数のサポートベクターで決まります。ただしSVMには制限があります。LiBSVMやLiblinearのオープンソースライブラリを使用せず、SVMのみを使用する場合、大量データの処理が大変な作業になります。理由は、SVMの計算プロセスには行列演算が関係しているためであり、サンプル数によって列や行の数が決まります。そのため大きいサンプルを処理するには時間がかかり、また計算プロセスのための空き容量が必要です。同様に、実際にHOGを活用するかどうかを決定する際は、その技術のメリットとデメリットを検討すべきです。参考までに、そのメリットとデメリットを以下にご紹介します。
メリット:
HOGは局所ユニットに利用されるため、ライトや色、その他の要素を無視して局所的形状情報を取得することが得意です。例えば、車両検知中は自動車の色を無視することで、特徴量の必要次元数を減らすことができます。またライトに関する技術的感度が低いため、一部が見えなくても車両を検知することができます。
デメリット:
HOGは、悪い見通しの処理、また車両の方向転換の検出もあまり得意ではありません。勾配の性質上、HOGはノイズに敏感なため、ブロックやセルが局所エリアのユニットに分かれた後、実際にはノイズを除去するためのガウシアンぼかしを頻繁に行わなければなりません。特徴量の次元数(セル、ブロック、ステップサイズなど)の決定は非常に厳しく、実際には最適な数に到達するために何度もトライしなければなりません。
いかがでしたでしょうか?この記事を読んで車両検知の現状について理解を深めていただければ幸いです。SVMとHOGの併用は計算負荷が高いですが、コストは低く、モデルの学習であれば標準CPUで実行できるため、このアプローチは現在では製品開発の中小企業の間で多く使われています。例えば、車載用カメラなどの小型部品の開発や生産は、一定してコストパフォーマンスが高く、有用性についても高いレベルを保っています。